You could have the best-looking website in your industry, but no one will find it if Google can’t crawl or index your pages.
Crawlability and indexability are the roots of organic visibility. They determine whether search engines see your pages at all, let alone rank them.
Think of it like this: crawlability is Google knocking on your door, and indexability is Google deciding whether to let your content move in. Ignore either, and you’re effectively ghosting Google, which isn’t how you build a lasting relationship.
Understanding and maintaining both are key for businesses looking to increase web traffic, conversions, and credibility.
Table of Contents
- What Crawlability Really Means
- Understanding Indexability
- Common Crawl & Index Issues Holding Your Website Back
- How to Check if Google Has Crawled and Indexed Your Site
- Proven Ways to Fix Crawlability and Indexability Problems
- Keeping Your Site Search-Ready: Ongoing SEO Maintenance Tips
- Final Thoughts: Stay Visible and Keep Google Close
- Glossary
What Crawlability Really Means
Crawlability describes how quickly search engine bots can access and browse your site. When Googlebot (the name of the web crawler used by Google Search) visits your website, it follows links, reads pages, and collects data to understand what your content is about. If something stops or slows down the bot, like broken links, blocked URLs, or slow page load times, your content may never reach the spotlight.
Here’s what typically gets in the way: blocked resources in your robots.txt file that unintentionally prevent crawling, infinite redirect loops that trap bots, JavaScript-heavy pages that delay rendering or hide content, and poor internal linking that leaves pages stranded with no entry point. The result? Google gives up before it even gets to the good stuff.
A crawlable site has clear, logical navigation, functional links, and a well-structured sitemap. If you make it easy for Google to explore, it will return more frequently, which is good news for your rankings.
Understanding Indexability
Crawlability is the first step, but indexability decides whether you’ve made it or not. This is where Google decides whether to include your page in its search index, which is the database of all discoverable web pages. If your site is crawlable but not indexable, you’re halfway there but remain invisible in search results.
Pages may fail to index for a variety of reasons, including “noindex” tags that instruct Google to ignore them, duplicate content where Google prefers another version, thin or low-quality content that adds no distinctive value, and canonicalisation issues where signals direct to the incorrect page.
Indexability is about clarity and intent. Ensure each page you want indexed contains unique, valuable content, correct canonical tags, and isn’t hidden behind crawl errors or blocked directives.
Common Crawl & Index Issues Holding Your Website Back
- Orphan pages: URLs not linked internally anywhere, so Google can’t find them.
- Incorrect canonical tags: Telling Google to index a different URL.
- Soft 404s: Pages that exist but return vague or inaccurate status codes.
- Duplicate URLs with tracking parameters: Wasting crawl budget on repetitive content.
- Massive JavaScript rendering: Slowing down discovery and indexing.
Even well-optimised sites can suffer from hidden technical problems. These issues collectively dilute your crawl efficiency. For businesses managing large sites, eCommerce stores, or regularly updated content, even a handful of these issues can result in hundreds of pages being neglected.
We often find that small technical oversights can cause significant visibility decreases. Fixing them can mean the difference between no traffic and a traffic surge.

How to Check if Google Has Crawled and Indexed Your Site
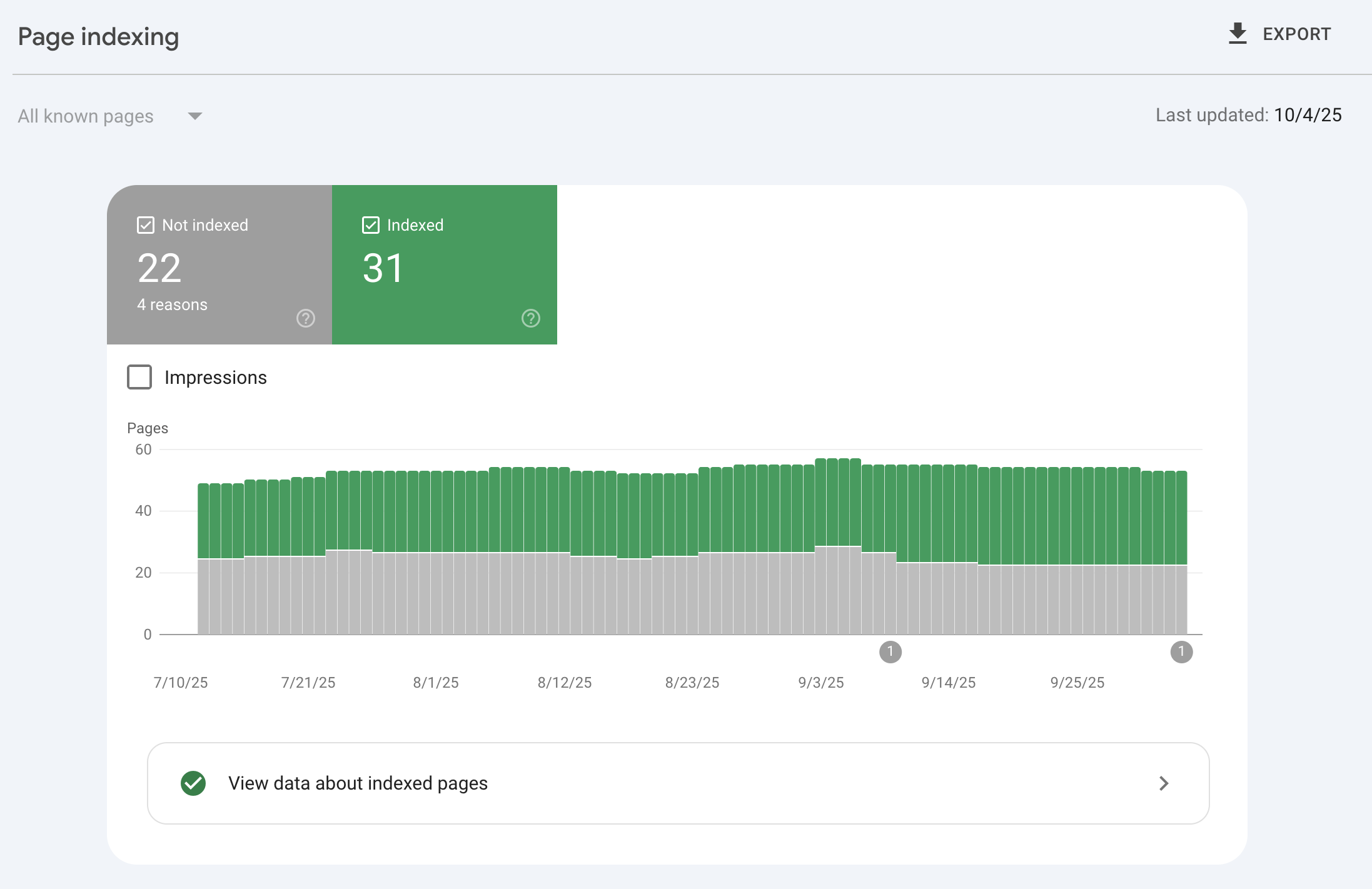
1. Use Google Search Console (GSC):
Go to the ‘Coverage’ or ‘Pages’ report to check which URLs are indexed, which are not, and why. Use the ‘URL Inspection Tool’ to determine the crawl and index status of individual pages. This tool also displays the exact last crawl date, any discovered errors, and whether Google selected a different canonical URL. If you’ve recently fixed a problem or added new content, you can even click ‘Request Indexing’ to speed up the process.
2. Try a “site:” search in Google:
Type ‘site:yourdomain.com’ into Google and you’ll see which pages are currently indexed. To go deeper, search for specific pages, for example, ‘site:yourdomain.com/blog’ to see all blog URLs. Or, you can search ‘site:yourdomain.com/page-title’ to confirm if a key landing page is appearing. If it doesn’t show up, Google hasn’t indexed it yet. You can also compare indexed results against your sitemap to identify missing URLs.
3. Review your crawl stats in GSC:
The ‘Crawl Stats’ report displays how frequently Googlebot visits your website, the response codes it sees, and the amount of data it downloads. A sudden decline in crawl activity may indicate deeper accessibility concerns or delayed server responses.
4. Use tools like SERanking or Screaming Frog:
These replicate how a bot crawls your website, highlighting blocked pages, redirects, missing metadata, and broken internal links. They’re invaluable for identifying issues before they harm your visibility.
If your content isn’t appearing where it should, it’s a clear sign that something is blocking the crawl or preventing indexation, and the sooner you find it, the easier it is to fix.
Proven Ways to Fix Crawlability and Indexability Problems
Robots.txt Files
Audit your robots.txt and meta directives to ensure you’re not accidentally blocking critical pages or folders. One misplaced slash here can accidentally block your entire site, so keep it tidy and regularly review it.
Submit an XML Sitemap
Submit an XML sitemap to help Google find and prioritise your most important pages, which is especially important for large sites or pages with limited backlinks. Make sure it updates automatically whenever new content is added.
Internal Linking
Improve internal linking so every page you care about is reachable within a few clicks. Internal links help Google understand your site hierarchy and allocate authority to important pages. When structured properly, they ensure crawlers flow naturally through your content instead of getting stuck in dead ends.
Improve Technical SEO
Increase site speed by compressing images, using caching, and considering a CDN. Faster sites not only get crawled more frequently but also keep users engaged.
Optimising Content
Remove duplicate content by consolidating overlapping pages with proper canonical tags or 301 redirects. Also, improve your content. Every indexed page should have unique, valuable, and keyword-relevant content. Google prioritises pages that provide depth, insight, and usability. You can also use keyword-rich anchor text for clarity and relevance.
Infinite Scrolling Pages
If your website has infinite scrolling pages, make sure that important content isn’t hidden behind endless AJAX loads or user-triggered actions. Search bots don’t scroll like people do, so if your products, blog posts, or articles only appear when someone scrolls, Google may never see them.
The solution is to use paginated URLs or load-more buttons with crawlable links. This ensures that every piece of content has a direct, accessible URL that Google can find and index.
Keeping Your Site Search-Ready: Ongoing SEO Maintenance Tips
Crawlability and indexability aren’t “set and forget” tasks. They evolve as your website grows and algorithms shift. To stay ahead, run regular technical audits to catch issues early, monitor new URLs in Google Search Console as soon as they’re published, and keep your sitemap dynamic, not static.
Update and refresh content regularly, as stale pages are crawled less often. Fix broken links or redirects quickly. Monitor server uptime to avoid crawl errors and ensure your hosting can handle traffic spikes without affecting performance.
Search visibility is built on consistency. Regular technical upkeep signals to Google that your site is active, reliable, and worth revisiting.
Final Thoughts: Stay Visible and Keep Google Close
In digital marketing, visibility is everything. Crawlability and indexability are your ticket into the game, and without them, no amount of great design or content will matter.
By fixing crawl and index issues, you’re not just helping Google understand your site; you’re helping your audience find you faster. We don’t just build beautiful websites, we make sure they’re discoverable, quick, and search-optimised from the ground up.
If you suspect Google’s been ghosted by your site, it’s time to bring it back into the spotlight. Need help making your site more crawlable and indexable? Get in touch with us today, and we’ll make sure Google never forgets your name.
Glossary
Crawlability – Crawlability determines how easily search engine bots can access and navigate your website to discover pages and content. If something blocks them, like broken links or a restrictive robots.txt file, your pages might never be seen or ranked.
Indexability – Indexability refers to whether a page that’s been crawled by a search engine is actually added to its database (the search index). If a page isn’t indexable, it won’t appear in search results even if it’s been crawled successfully.
Googlebot – Googlebot is Google’s automated web crawler. It browses websites, follows links, and collects information about pages so Google can understand and rank them in search results.
Robots.txt – A small text file placed on your website that notifies search engines which pages or folders they can or can’t crawl. One incorrect line in this file can unintentionally block your entire site from search engines.
Meta Directives – HTML tags that give search engines page-specific instructions, such as whether to index a page or follow its links. For example, <meta name=”robots” content=”noindex”> tells Google not to include that page in search results.
Canonicalisation – The process of choosing a preferred URL when multiple pages have similar or identical content. Proper canonicalisation helps avoid duplicate content problems and ensures search engines focus on the correct version.
Canonical Tag – A tag that helps search engines find the main version of a page when multiple URLs have similar or duplicate content. It prevents duplicate content issues and ensures ranking signals go to the correct page.
Crawl Budget – The amount of time and resources Google uses to crawl a website. If your site has too many errors, duplicates, or low-value pages, you can waste crawl budget and reduce how often Google visits your most important pages.
XML Sitemap – A structured file that lists all the URLs you want search engines to find and index. It acts like a roadmap, helping crawlers efficiently find your site’s main pages.
Orphan Page – A webpage that isn’t linked to anywhere else on your site, making it invisible to search engine crawlers unless it’s included in your sitemap.
Soft 404 – A page that appears as a valid page to users but returns an incorrect response code to Google, suggesting the content doesn’t exist. This confuses search engines and can waste crawl budget.
Paginated URLs – URLs that separate long lists or continuous scrolls of content into multiple numbered pages (like /page/2, /page/3). They help search engines access content that might otherwise be hidden behind an infinite scroll.
Infinite Scroll – A design feature that continuously loads new content as a user scrolls down the page, instead of using traditional pagination. It’s key to ensure this content is also accessible through crawlable links.
AJAX Load – A way of loading new content onto a page without reloading it, often used for infinite scrolling or “load more” buttons. While user-friendly, content loaded this way isn’t always seen by search engines.
Noindex Tag – A meta tag that tells search engines not to include a specific page in their index. Useful for private or duplicate pages, but can cause issues if added to important content by mistake.